

Sem servidor há 3 meses
Sem servidor há 3 meses
Minha experiência até agora com Serverless da AWS!

No final de Agosto embarquei no desafio de explorar uma nova arquitetura num ambiente produtivo, Serverless na AWS…
Desde que iniciei na área de desenvolvimento lembro de como era falado sobre Serverless, até por que em meados de 2018 foi quando começou o grande hype sobre essa nova arquitetura na qual não se utiliza de nenhum servidor!
Hoje vou te contar um pouco sobre o que tive de experiência até agora, o que aprendi e o que espero daqui pra frente.
Mas já te adianto, que tem sido incrível… saber utilizar da forma correta te poupa MUITO tempo e esforço em softwares de diversos tamanhos.
Se gosta do meu conteúdo aqui por escrito, não se esqueça de se inscrever por aqui! 🙏
Vamos falar de história antes - a evolução da nuvem
No início dos anos 2000, a computação em nuvem era um conceito nascente. Os provedores de nuvem ofereciam serviços de infraestrutura como serviço (IaaS), que permitiam aos clientes provisionar e gerenciar seus próprios servidores virtuais.
Esse modelo de nuvem requeria que os clientes tivessem um certo nível de conhecimento técnico para configurar e gerenciar seus servidores virtuais. Isso limitou o uso da computação em nuvem a empresas e organizações com equipes de TI experientes.
A ascensão dos containers
A ascensão dos containers no final dos anos 2000 e início dos anos 2010 simplificou a adoção da computação em nuvem. Os containers são unidades de software que empacotam código, libs e dependências em um ambiente isolado. Isso permite que as aplicações sejam executadas em qualquer infraestrutura de nuvem, sem a necessidade de reconfiguração ou reinstalação, dando mais liberdade para as pessoas devs.
O Docker, lançado em 2013, tornou os containers mais acessíveis e fáceis de usar. Isso levou a um aumento no uso de containers em aplicações em nuvem.
O surgimento do serverless
Em 2014, a Amazon Web Services (AWS) lançou a Lambda, um serviço de computação sem servidor que permite as pessoas desenvolvedoras executar código sem provisionar ou gerenciar servidores.
A Lambda foi um marco importante na evolução da computação em nuvem, pois simplificou ainda mais o desenvolvimento e a implantação de aplicações em nuvem.
O sucesso da Lambda levou outros provedores de nuvem a lançar seus próprios serviços de computação sem servidor. Em 2015, o Google Cloud Platform lançou o Cloud Functions, e o Microsoft Azure lançou o Azure Functions.
A proliferação do serverless
O serverless se tornou um paradigma de computação cada vez mais popular nos últimos anos. Isso se deve a uma série de fatores, incluindo:
A simplicidade e a facilidade de uso do serverless
A escalabilidade e a disponibilidade automáticas do serverless
O custo reduzido do serverless (quando bem desenvolvido!)
O que é Serverless?
Serverless é um modelo de computação em nuvem em que o provedor de nuvem gerencia a infraestrutura e os recursos subjacentes, como servidores, armazenamento e rede. Os desenvolvedores podem se concentrar na lógica de negócios de suas aplicações, sem se preocupar com a administração da infraestrutura.
Com o Serverless, os pessoas desenvolvedoras não precisam provisionar ou gerenciar servidores.
Eles simplesmente escrevem o código de suas aplicações e o enviam para a nuvem.
O provedor de nuvem então gerencia o provisionamento, o dimensionamento e a execução do código, de acordo com a demanda.
Exemplo mais simples, seria nessa demo que encontrei em um artigo muito bacana na qual foi criado um serviço que usa Alexa com Serverless para processar comandos de voz, reconhecimento de fala e outros serviços.
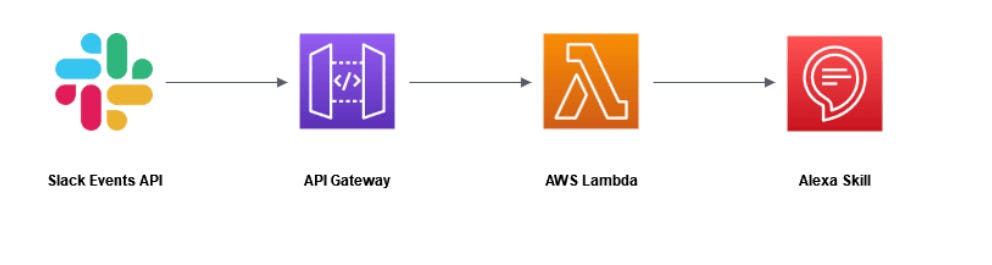
fonte: https://www.antstack.com/blog/serverless-integration-of-slack-with-alexa/
Como o Serverless funciona na AWS?
Na AWS, o Serverless é implementado por meio de uma variedade de serviços, incluindo:
AWS Lambda: é um serviço de computação sem servidor que permite executar código sem provisionar ou gerenciar servidores. As funções Lambda são invocadas em resposta a eventos, como solicitações HTTP, mensagens de fila ou alterações de dados.
AWS API Gateway: é um serviço de API que permite criar, publicar e gerenciar APIs REST e WebSocket. O API Gateway pode ser usado para conectar funções Lambda a clientes externos.
AWS DynamoDB: é um banco de dados NoSQL totalmente gerenciado que é ideal para aplicações de alto tráfego e baixa latência.
AWS S3: é um serviço de armazenamento de objetos que fornece armazenamento seguro e durável para objetos de qualquer tamanho.
Vamos mais a fundo de como pode ser utilizado na AWS::
Aplicação web que processa solicitações HTTP
Uma aplicação web que processa solicitações HTTP pode ser implementada usando funções Lambda que são invocadas em resposta a solicitações HTTP. O API Gateway pode ser usado para conectar as funções Lambda a clientes externos.
Por exemplo, uma aplicação web que permite aos usuários fazer upload de arquivos pode ser implementada usando uma função Lambda que é invocada em resposta a solicitações HTTP de upload de arquivos. A função Lambda pode então armazenar os arquivos no S3.
Serviço de processamento de dados em tempo real
Um serviço de processamento de dados em tempo real pode ser implementado usando funções Lambda que são invocadas em resposta a eventos, como alterações de dados. O DynamoDB pode ser usado para armazenar os dados de entrada e saída.
Por exemplo, um serviço de streaming de vídeo pode ser implementado usando funções Lambda que são invocadas em resposta a novas transmissões de vídeo. As funções Lambda podem então processar as transmissões de vídeo e gerar metadados, como o título do vídeo, a duração do vídeo e a classificação do vídeo.
Aplicativo de análise de dados
Um aplicativo de análise de dados pode ser implementado usando funções Lambda que são invocadas em resposta a solicitações de análise. O S3 pode ser usado para armazenar os dados de análise.
Por exemplo, um aplicativo de análise de vendas pode ser implementado usando funções Lambda que são invocadas em resposta a solicitações de análise de vendas. As funções Lambda podem então acessar os dados de vendas armazenados no S3 e gerar relatórios de vendas.
Benefícios do Serverless na AWS
Os principais benefícios do Serverless na AWS incluem:
Escalabilidade: os recursos são dimensionados automaticamente de acordo com a demanda, o que ajuda a reduzir os custos.
Facilidade de uso: os desenvolvedores podem se concentrar na lógica de negócios de suas aplicações, sem se preocupar com a administração da infraestrutura.
Redução de custos: com serverless pagamos pelo que usamos, isso pode ser muito econômico, ou muito custoso dependendo de como a pessoa que esta utilizando desenvolve as lambdas
Aplicações viáveis para o Serverless
O Serverless é uma opção viável para uma variedade de aplicações, incluindo:
Aplicações web e móveis: o Serverless pode ser usado para implementar a lógica de back-end de aplicações web e móveis.
Serviços de processamento de dados: o Serverless pode ser usado para implementar serviços de processamento de dados em tempo real ou por lote.
Aplicações de análise de dados: o Serverless pode ser usado para implementar aplicações de análise de dados.
Redução de custos com serverless é um tiro no pé? 🤨
Realmente o que é mais presente em softwares que utilizam essa tecnologia é ver custos altos, justamente por que utilizando lambdas e associados de serverless é muito simples de começar, e muitas das vezes não se inícia pensando em escalonamento.
Nesses meses, indo em eventos sobre Serverless, criando projetos, no trabalho e conversando com especialistas notei alguns pontos que fazem a galera gastar muito com serverless, vamos lá
1 - Não fazer um tooling offline
Apontas AWS pra codificar num ambiente de desenvolvimento dev por exemplo, custo muito.
Cada requisição irá pra conta final do mês.
O ideal é ter um localStack ou um serverless offline para rodar no projeto a fim de que tenha um ambiente local estável.
2 - Configuração de CDN
Para otimizar um CDN com serverless, usar um serviço de CDN da nuvem, como o Amazon CloudFront ou o Google Cloud CDN. Esses serviços oferecem uma variedade de recursos que podem ajudar a melhorar o desempenho, como:
Caching: o conteúdo é armazenado em cache nos servidores do CDN, o que reduz a necessidade de acessar os servidores de origem.
Escalabilidade automática: o CDN é dimensionado automaticamente de acordo com a demanda, o que ajuda a garantir que o conteúdo esteja sempre disponível.
Rede global: o CDN tem uma rede global de servidores, o que pode ajudar a melhorar o desempenho para usuários em qualquer lugar do mundo.
3 - Renderizar apenas o necessário
Fazer uma análise brusca em lambdas, por serem simples de desenvolver o cenário mais comum é que tudo seja feito por lambdas, mas realmente tem a necessidade disso?
No meu trabalho atual foi uma das análises que o time fez logo que entrei, fiquei impressionada que o fato de ter lambdas demais com o agent de um serviço de observalidade afeta demais o cold start das lambdas.
Claro, que não é apenas movendo as responsabilidades de lambdas para apis que muda o cenário, mas acho que uma análise é bem válida para evitar muito custo!
4 - Falta de testes end to end
Tendo um ambiente local que possa rodar serverless facilita na criação de testes E2E afim de evitar retrabalhos e garantir que custos possam ser reduzidos
Existem muitos motivos, mas quis citar os que achei principais até para que o estigma de que Serverless é caro, isso é mito.
Um software com containers e na nuvem do formato tradicional pode ser caro também, tudo depende de quem configura ou desenvolve, no caso nós.
Estudar e entender é fundamental, pois Serverless pode ser muito útil para diversos cenários!
Dicas para a semana 🔥
Evento
FALANDO EM SERVERLESS, dia 13 de Deembro vai rolar um super evento da NodeBR aqui em São Paulo no escritório do Grupo Primo, com o tema Serverless, bora junto da gente!