
Boas práticas em APIs Rest
Sabia que o básico te diferencia?

Com o uso massivo de IA generativa, ficou mais fácil “fazer funcionar” do que “desenvolver bem”.
Sem sequer um norte arquitetural, temos visto cada vez mais APIs com contratos frágeis, alto acoplamento e rotas lentas.
Na newsletter de hoje quero trazer os fundamentos RESTful... do modelo de recursos às garantias de idempotência e transação e te mostrar por que endpoints devem ser orientados a entidades, não a “casos de uso”.
Isso é todo um case pessoal, estou criando um projeto do zero e ao abrir o Pull request pra revisão percebi como cometi "pequenos" erros por falta de visão holística e não pratica dos fundamentos bem implementados....
O que tudo bem acontecer, mas infelizmente precisa ser notado o quanto antes
Detalhes que te diferenciam...
Se você acha que isso é "balela", te digo que saber esses fundamentos te diferencia muito para vagas na gringa e melhor que isso, se MANTER na gringa.
E muitas pessoas se questionam desses processos seletivos e te o pessoal da Coders, a mentoria especializada em levar devs pra gringa, liberou somente pra quem acompanha a newsletter 60 minutos de uma consultoria gratuita para entender seu momento de carreira para trabalhar fora do país....
🔥 E é uma baita oportunidade, vou deixar o link para você entrar em contato com o time de consultores da Coders -> https://bit.ly/3R7KYbF

Contratos Consistentes
REST é um estilo arquitetural, não um protocolo.
Os princípios são: client–server, stateless, cacheable, interface uniforme (recursos + representações), layered system e (opcional) code on demand...no dia a dia com HTTP/JSON:
Formato canônico (JSON): em requisições e respostas (Content-Type e Accept: application/json; charset=utf-8).
Recursos (substantivos, plural): /books, /loans, /users. O verbo está no método HTTP (GET/POST/PUT/PATCH/DELETE).
Aninhamento lógico moderado: até dois níveis ex. /users/{userId}/loans. Além disso, preferir links (HATEOAS leve) para evitar URIs impraticáveis.
Paginação, filtros e ordenação: sempre importante entendermos que uma páginação por domínio que não seja apenas por usuário é bem importante, grande parte das vezes são a fachada inicial pro nosso client(app ou app) - GET /catalog?page=1&limit=20&author=...&sort=+title,-year
Versionamento explícito: /v1/... e evolução compatível (deprecar antes de remover).
Cache HTTP bem definido: Cache-Control, ETag/If-None-Match, Last-Modified/If-Modified-Since, Vary quando necessário.
Por quê isso importa???? Contratos consistentes habilitam discoverability, cache intermediário, tooling automático (OpenAPI- swagger), canary releases e redução de latência sem mudanças no client.
Exemplo de uma api criada para um projeto pessoal:
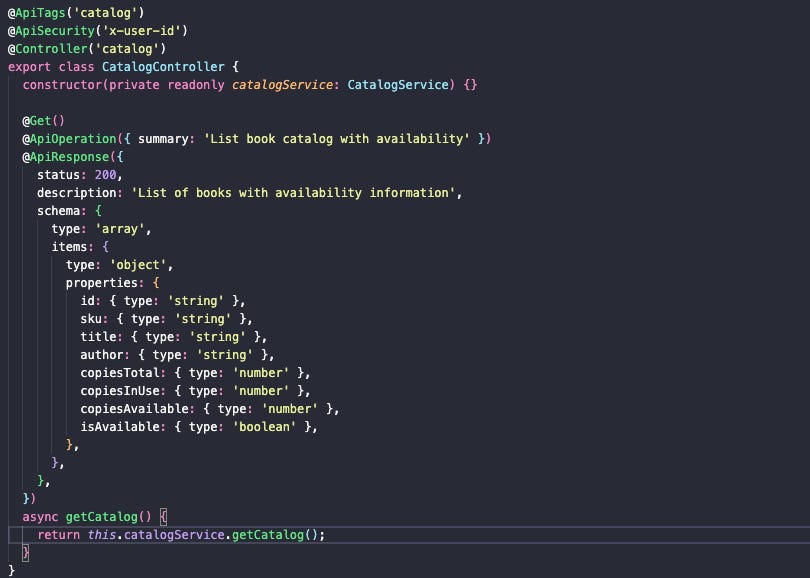
Endpoints por entidade e não "casos de uso"
APIs REST são resource-oriented. Casos de uso se expressam via transições de estado e sub-recursos, não por verbos na URI.
E muitas das vezes nas lógicas dos respectivos serviços pode agregar outras tabelas, o que pode gerar uma quantidade exorbitante de JOINs
Vou trazer o exemplo do projeto que estou desenvolvendo:
✅ Correto:
POST /loans — cria empréstimo
PATCH /loans/{id}/return — transição para RETURNED
GET /books/{sku} — detalhe
GET /users/{userId}/loans — relação natural
🚨 Evitar:
POST /createLoanFromScanner, POST /loanBookUseCase
Efeitos colaterais de “caso de uso” na URI: quebra de semântica HTTP, inviabiliza cache/proxies, acopla a API a workflows específicos, aumenta a complexidade de SQL (JOINs desnecessários) e degrada performance.
Se o cliente precisar de composições, é mais preferível usarmos recursos de consulta (/search) com parâmetros bem definidos, ou aggregation no BFF(backend for frontend), mantendo a API de domínio limpa.
Idempotência
Semântica HTTP para métodos seguros (GET, HEAD) que não alteram estado; idempotentes (PUT, DELETE) podem alterar, mas o efeito repetido é o mesmo. POST, por padrão, não é idempotente.
É completamente louvável acessar um endpoint de lista que você pode requerir diversas vezes, que seu resultado se mantém consistente...
Problema real: retries (rede/gateway) podem criar vários empréstimos (novamente voltando pro projeto que estou criando)
Padrão recomendado: Idempotency-Key em POST /loans.
O cliente envia Idempotency-Key: <uuid>.
O servidor guarda o resultado da 1ª execução por janela, pode ser em 24hs.
Repetições com a mesma chave retornam a mesma resposta sem novos efeitos.
Se a mesma chave vier com payload diferente, responder 409 Conflict.
Em paralelo, reforçar com unicidade de negócio (ex.: unique(userId, sku, status='ACTIVE')).
Por que não só transação? Idempotência lida com reentrega em outra requisição/conexão (camada de aplicação). Transação lida com atomicidade dentro de uma execução.
Alternativa válida: criação determinística por PUT /loans/{id}
Transações: ACID, isolamento e concorrência sem sustos
Invariantes do domínio (Library Loans).
copiesInUse ≤ copiesTotal (estoque);
activeLoansByUser ≤ 2;
integridade referencial (FKs).
Implementação robusta:
Defesa em profundidade: invariantes no banco (constraints/índices/checks) e na aplicação.
$transaction (Prisma): agrupar “criar empréstimo + atualizar estoque” de forma atômica.
Isolamento e corrida: Postgres padrão é READ COMMITTED; para contenção forte, considerar SERIALIZABLE em trechos críticos (ciente de retries).
Locking consistente: definir ordem de locks (ex.: Book → Loan) e backoff exponencial para 40001/40P01.
Optimistic vs. pessimistic: optimistic locking via version/updatedAt em cenários de baixa colisão; pessimistic (SELECT … FOR UPDATE) para hot rows como estoque.
Processos distribuídos: publicar eventos com Outbox Pattern; o relay só envia após commit, evitando phantoms em consumidores.
DTOs: evitar explosão e trocas de contrato
Risco: um DTO por “caso de uso” gera duplicação, mappers prolixos e inconsistência
DTO por entidade (entrada/saída); variações pequenas por composição (PartialType, PickType, IntersectionType).
Componentes reutilizáveis no OpenAPI (schemas para Sku, UserId).
Mensagens de validação padronizadas (class-validator/Zod).
DTO ≈ representação do recurso (menos mapeamento, menos drift).
Evolução compatível: marcar deprecated antes de remover campos; documentar sunset.
Erros, observabilidade e segurança
Erros padronizados: utilizar um problem details padronizado para formato previsível, se cada classe ou api usa um tratamento diferente pode gerar enormes inconsistências.
Correlação: incluir traceId/requestId em logs e respostas; OpenTelemetry para encadear HTTP → DB.
Logs estruturados (JSON) com nível, context e campos úteis (latência, usuário, recurso).
Segurança por padrão: TLS, JWT + refresh, RBAC (princípio do mínimo privilégio), rate limiting e secrets fora do código.
Privacidade e cache: cuidado com Cache-Control em endpoints autenticados (tipicamente private, no-store).
Projetar APIs RESTful vai além de “fazer requisições funcionarem”... e vai muuuito além do que só pedir um prompt e receber o retorno.
Envolve modelar recursos estáveis, respeitar a semântica HTTP, tornar criações idempotentes, preservar invariantes com transações e manter contratos enxutos via DTOs por entidade.
Num cenário em que a IA acelera a entrega, é exatamente essa disciplina de fundamentos que garante qualidade, segurança e performance de longo prazo.
Faz sentido pra vocês
Rolês da semana 🔥
Bora que dicas maneiras pra essa semana?
[ARTIGO] - Boas práticas de segurança de API
[ARTIGO] - Refatorando ideias
[VÍDEO] - O MAIOR SUPPLY CHAIN ATTACK DA HISTÓRIA? — O que realmente aconteceu e qual o real impacto disso? - Super vídeo do querido amigo Weslley Araújo