
BFF é Over-Engineering?
será que compensa mais um microservice?

Introdução
Estou há quase um ano trabalhando com o padrão BFF (Backend for Frontend), uma arquitetura responsável por facilitar a comunicação entre o backend e os desenvolvedores que consomem APIs. O BFF centraliza os modelos de payloads e dá mais independência aos serviços.
Um dos fatores mais interessantes é o fato de que ele funciona como uma "black box". Ou seja, os componentes são projetados de forma que sua implementação “não importe” a priori para o frontend que os consome.
O principal objetivo do Backend for Frontend é customizar o backend para cada frontend, evitando trazer dados desnecessários e otimizando as responses.
Quando Surgiu a Ideia do BFF?
Pesquisas indicam que o conceito de BFF surgiu por volta de 2015 e foi popularizado pela equipe de engenharia da SoundCloud. Ele foi criado como uma solução para os desafios enfrentados no desenvolvimento de aplicações para múltiplas plataformas (web, mobile, smart devices), onde um backend único não atendia bem às necessidades específicas de cada frontend.
A principal motivação para o BFF foi evitar que os frontends precisassem lidar com dados brutos e lógica desnecessária. Assim, cada tipo de cliente teria um backend adaptado, melhorando a performance e a experiência do usuário. Desde então, essa abordagem foi amplamente adotada em arquiteturas modernas, especialmente em aplicações distribuídas baseadas em microservices.
Por Que o BFF Pode Ser Over-Engineering?
Levando em consideração que um BFF é utilizado como um microservice por diversos times, ele pode herdar a maior dor desse modelo: a complexidade.
Quem nunca teve problemas para realizar o deploy de um serviço compartilhado por diversos times? E nem estou falando apenas de pipelines multidisciplinares, mas também da dificuldade de manter o código padronizado e atualizado corretamente nos ambientes.
O BFF pode ser dividido tanto por APIs quanto por serviços. Hoje, trabalho com monorepos, onde diferentes repositórios possuem responsabilidades distintas. Os endpoints direcionados para mobile são colocados no BFF Mobile, enquanto os destinados à web vão para o BFF Web.
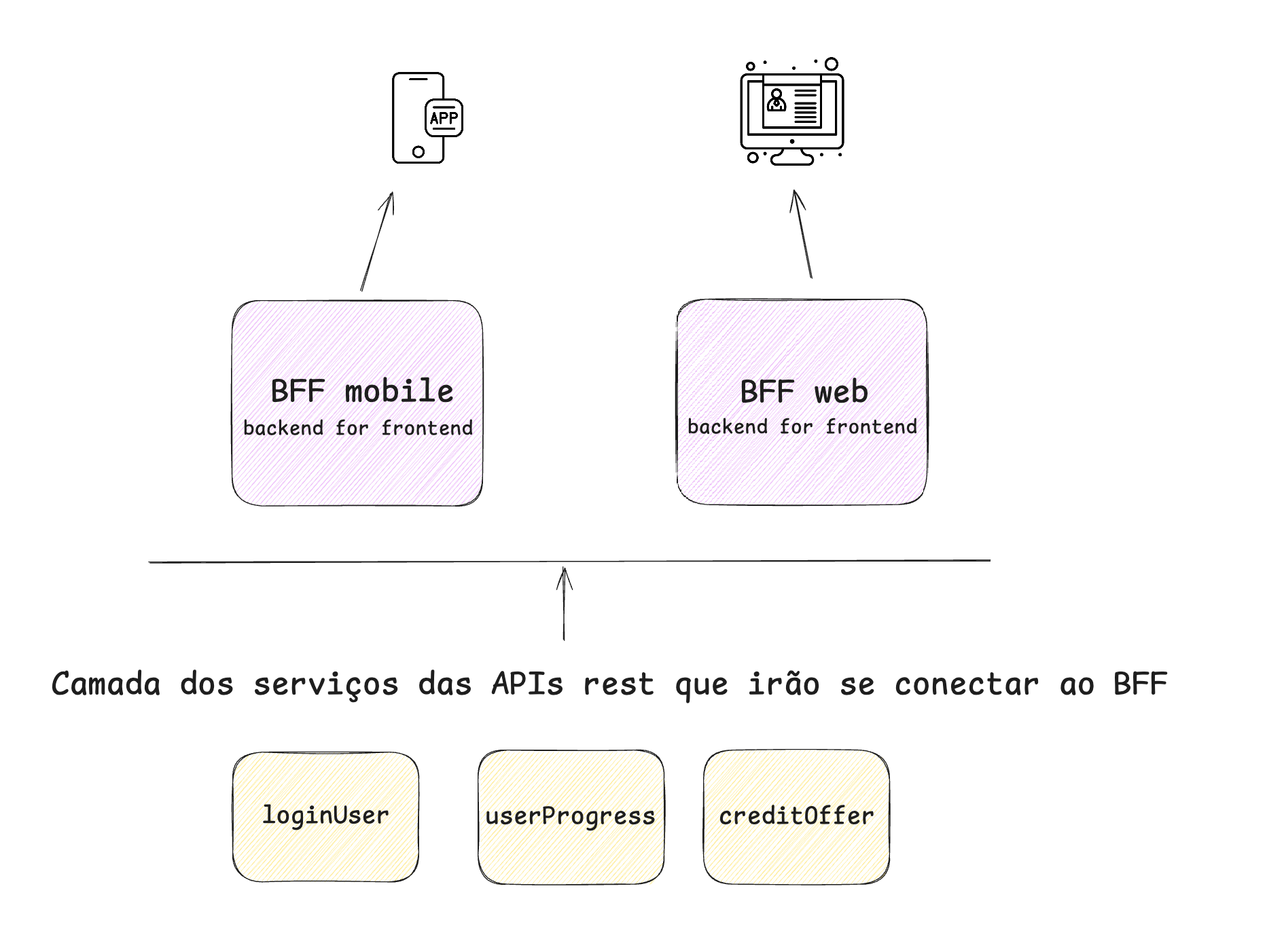
Um Case Interessante
Um dos maiores desafios do BFF, como mencionado, pode ser a complexidade — tanto no código quanto nas respostas — devido ao uso compartilhado entre diversos times.
No entanto, um case bacana não está relacionado diretamente à refatoração de um BFF para ganho de performance (até porque, sendo um microservice, ele pode se tornar grande e complexo de refatorar). O case, na verdade, trata de um sistema de tradução que ajudou a reduzir a complexidade para o frontend.
O problema era que o frontend precisava implementar diversas lógicas para traduzir campos que eram ENUM. A solução foi implementar um decorator dentro do BFF, tornando essa conversão dinâmica. Dessa forma, os dados já chegavam traduzidos corretamente ao frontend, reduzindo significativamente a complexidade no consumo das APIs.
Conclusão
BFF pode ser implementado com diversas tecnologias. Atualmente, utilizo KOA, mas acredito que qualquer framework simples pode atender bem ao propósito.
No entanto, o maior desafio do BFF está na complexidade gerada entre times. Por isso, minha recomendação é que, desde o início do desenvolvimento de um projeto BFF, sejam adotadas boas práticas, como:
Inserção de linters
Uso do Husky para análise de commits
Implementação de testes simples para validar fluxos básicos
Creio que ajuda a evitar dores de cabeça no futuro e a garantir que o BFF continue sendo uma solução viável, sem se tornar um problema de over-engineering.
Espero que tenha curtido o insight da semana, vou deixar abaixo minhas recomendações 💖